Defining a simple example case:
- German credit classification task
- Random forests with 100 trees
- Holdout split (TBI)
- Measure: Classification error
task = tsk("german_credit")
learner = lrn("classif.ranger", num.trees = 500)
measure = msr("classif.ce")PFI
Simple case without resampling
Default behavior will internally construct standard holdout resampling with default ratio
Calculating PFI:
pfi = PFI$new(
task = task,
learner = learner,
measure = measure
)
# Stores parameter set to calculate PFI in different ways
pfi$param_set
#> <ParamSet>
#> id class lower upper nlevels default value
#> <char> <char> <num> <num> <int> <list> <list>
#> 1: relation ParamFct NA NA 2 difference difference
set.seed(123)
# Default behavior should be sane
pfi$compute()
#> age amount credit_history
#> 0.009009009 0.015015015 0.003003003
#> duration employment_duration foreign_worker
#> 0.021021021 0.000000000 0.006006006
#> housing installment_rate job
#> 0.018018018 0.033033033 -0.009009009
#> number_credits other_debtors other_installment_plans
#> 0.003003003 -0.006006006 0.003003003
#> people_liable personal_status_sex present_residence
#> -0.003003003 0.012012012 0.000000000
#> property purpose savings
#> 0.006006006 -0.003003003 0.009009009
#> status telephone
#> 0.036036036 0.009009009Q: Should $compute() be run on construction? Between the
call to $new() and $compute() there’s nothing
that needs to happen technically, as long as the relation
param could be set directly.
Does not recompute if not needed:
pfi$compute(relation = "difference")
#> age amount credit_history
#> 0.009009009 0.015015015 0.003003003
#> duration employment_duration foreign_worker
#> 0.021021021 0.000000000 0.006006006
#> housing installment_rate job
#> 0.018018018 0.033033033 -0.009009009
#> number_credits other_debtors other_installment_plans
#> 0.003003003 -0.006006006 0.003003003
#> people_liable personal_status_sex present_residence
#> -0.003003003 0.012012012 0.000000000
#> property purpose savings
#> 0.006006006 -0.003003003 0.009009009
#> status telephone
#> 0.036036036 0.009009009Recomputes if param changes, stores new param
pfi$compute(relation = "ratio")
#> age amount credit_history
#> 1.0574713 1.0344828 1.0919540
#> duration employment_duration foreign_worker
#> 1.0689655 1.0114943 1.0000000
#> housing installment_rate job
#> 1.0344828 1.0459770 0.9655172
#> number_credits other_debtors other_installment_plans
#> 0.9655172 1.0114943 1.0114943
#> people_liable personal_status_sex present_residence
#> 1.0229885 1.0229885 1.0000000
#> property purpose savings
#> 1.0344828 1.0114943 1.0344828
#> status telephone
#> 1.1149425 1.0114943
pfi$param_set
#> <ParamSet>
#> id class lower upper nlevels default value
#> <char> <char> <num> <num> <int> <list> <list>
#> 1: relation ParamFct NA NA 2 difference ratioQ: When $compute() is called again its default value for
"relation" (i.e. "difference") is used, which
doesn’t seem ideal. Maybe this default should be the param stored in the
object itself rather than feel like a separate function.
pfi$compute()
#> age amount credit_history
#> 0.015015015 -0.012012012 0.000000000
#> duration employment_duration foreign_worker
#> 0.057057057 -0.012012012 -0.003003003
#> housing installment_rate job
#> -0.003003003 0.009009009 -0.003003003
#> number_credits other_debtors other_installment_plans
#> -0.006006006 -0.006006006 -0.012012012
#> people_liable personal_status_sex present_residence
#> -0.006006006 0.006006006 -0.009009009
#> property purpose savings
#> -0.003003003 -0.024024024 0.027027027
#> status telephone
#> 0.021021021 -0.003003003Retrieve scores and convert to DT:
pfi$importance
#> age amount credit_history
#> 0.015015015 -0.012012012 0.000000000
#> duration employment_duration foreign_worker
#> 0.057057057 -0.012012012 -0.003003003
#> housing installment_rate job
#> -0.003003003 0.009009009 -0.003003003
#> number_credits other_debtors other_installment_plans
#> -0.006006006 -0.006006006 -0.012012012
#> people_liable personal_status_sex present_residence
#> -0.006006006 0.006006006 -0.009009009
#> property purpose savings
#> -0.003003003 -0.024024024 0.027027027
#> status telephone
#> 0.021021021 -0.003003003
as.data.table(pfi)
#> feature importance
#> <char> <num>
#> 1: age 0.015015015
#> 2: amount -0.012012012
#> 3: credit_history 0.000000000
#> 4: duration 0.057057057
#> 5: employment_duration -0.012012012
#> 6: foreign_worker -0.003003003
#> 7: housing -0.003003003
#> 8: installment_rate 0.009009009
#> 9: job -0.003003003
#> 10: number_credits -0.006006006
#> 11: other_debtors -0.006006006
#> 12: other_installment_plans -0.012012012
#> 13: people_liable -0.006006006
#> 14: personal_status_sex 0.006006006
#> 15: present_residence -0.009009009
#> 16: property -0.003003003
#> 17: purpose -0.024024024
#> 18: savings 0.027027027
#> 19: status 0.021021021
#> 20: telephone -0.003003003
#> feature importanceWith resampling
learner = lrn("classif.ranger", num.trees = 100)
resampling = rsmp("cv", folds = 3)
measure = msr("classif.ce")
pfi = PFI$new(
task = task,
learner = learner,
resampling = resampling,
measure = measure
)
pfi$resampling
#> <ResamplingCV>: Cross-Validation
#> * Iterations: 3
#> * Instantiated: TRUE
#> * Parameters: folds=3
pfi$resample_result
#> NULL
pfi$compute(relation = "difference")
#> age amount credit_history
#> 0.004996014 0.016007025 0.028004052
#> duration employment_duration foreign_worker
#> 0.021995049 0.004004004 0.001001001
#> housing installment_rate job
#> 0.007993023 0.013990038 0.003000006
#> number_credits other_debtors other_installment_plans
#> 0.000000000 0.003995013 0.009998022
#> people_liable personal_status_sex present_residence
#> 0.001996008 0.003998010 0.005997015
#> property purpose savings
#> 0.012989037 0.011002020 0.027989067
#> status telephone
#> 0.042995091 0.007004010
pfi$resample_result
#> <ResampleResult> with 3 resampling iterations
#> task_id learner_id resampling_id iteration warnings errors
#> german_credit classif.ranger cv 1 0 0
#> german_credit classif.ranger cv 2 0 0
#> german_credit classif.ranger cv 3 0 0
pfi$importance
#> age amount credit_history
#> 0.004996014 0.016007025 0.028004052
#> duration employment_duration foreign_worker
#> 0.021995049 0.004004004 0.001001001
#> housing installment_rate job
#> 0.007993023 0.013990038 0.003000006
#> number_credits other_debtors other_installment_plans
#> 0.000000000 0.003995013 0.009998022
#> people_liable personal_status_sex present_residence
#> 0.001996008 0.003998010 0.005997015
#> property purpose savings
#> 0.012989037 0.011002020 0.027989067
#> status telephone
#> 0.042995091 0.007004010Different measure:
Q: Maybe it would be worth allowing to change measure post-hoc?
learner$predict_type = "prob"
pfi = PFI$new(
task = task,
learner = learner,
resampling = resampling,
measure = msr("classif.auc")
)
pfi$compute(relation = "ratio")
#> age amount credit_history
#> 1.0119854 1.0182071 1.0261672
#> duration employment_duration foreign_worker
#> 1.0391916 1.0176308 1.0006448
#> housing installment_rate job
#> 1.0050683 0.9996105 0.9996705
#> number_credits other_debtors other_installment_plans
#> 1.0012332 1.0040648 1.0097691
#> people_liable personal_status_sex present_residence
#> 0.9996198 1.0010624 0.9972150
#> property purpose savings
#> 1.0104244 1.0087439 1.0273154
#> status telephone
#> 1.1509158 1.0025541
pfi$compute(relation = "difference")
#> age amount credit_history
#> 1.219438e-02 7.990804e-04 1.942118e-02
#> duration employment_duration foreign_worker
#> 3.469820e-02 7.473255e-03 6.846385e-04
#> housing installment_rate job
#> 2.851689e-03 3.310377e-03 -4.428262e-04
#> number_credits other_debtors other_installment_plans
#> -1.266753e-03 6.770134e-03 8.964666e-03
#> people_liable personal_status_sex present_residence
#> 1.633042e-03 2.295840e-03 6.110152e-05
#> property purpose savings
#> 1.331438e-03 4.640028e-03 7.728800e-03
#> status telephone
#> 1.171140e-01 2.073551e-03Q: Results are importance scores averaged over resampling iterations
to ensure the “named numeric” return format. But what about the
individual scores across resampling iterations?
If we want to attempt uncertainty quantification or at least also report
SDs there needs to be a data.table return type.
LOCO
Same setup but now using LOCO, which differs in that it internally
needs to refit the model.
Notably, the Task object does not need to be modified, as
it suffices to adjust the .$col_roles$feature property.
learner = lrn("classif.ranger", num.trees = 100)
loco = LOCO$new(
task = task,
learner = learner,
resampling = resampling,
measure = msr("classif.ce")
)
loco$compute()
#> age amount credit_history
#> -4.996014e-03 5.994018e-06 3.006000e-03
#> duration employment_duration foreign_worker
#> -9.890130e-04 8.991027e-06 -7.984032e-03
#> housing installment_rate job
#> -1.699903e-02 -1.999005e-03 5.994018e-06
#> number_credits other_debtors other_installment_plans
#> -1.598904e-02 -6.003009e-03 -1.701702e-02
#> people_liable personal_status_sex present_residence
#> -8.008008e-03 -5.005005e-03 -3.986022e-03
#> property purpose savings
#> -6.003009e-03 -7.993023e-03 -8.982036e-03
#> status telephone
#> 2.400304e-02 -4.004004e-03Aggregating results
scores_rel = data.table(
feature = task$feature_names,
PFI = pfi$compute(relation = "ratio"),
LOCO = loco$compute(relation = "ratio")
)
scores_rel |>
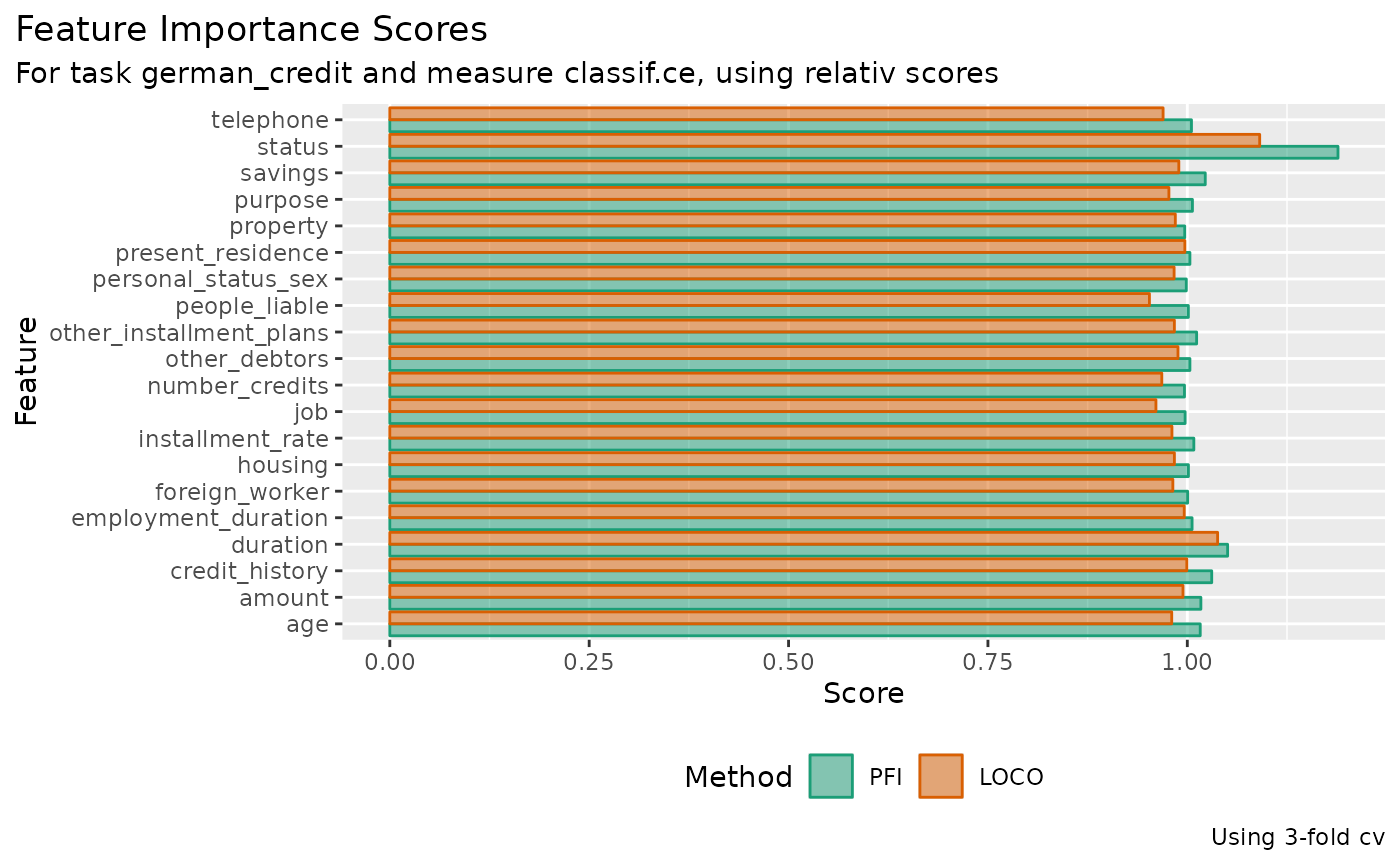
knitr::kable(digits = 4, caption = "Importance scores (ratio)")| feature | PFI | LOCO |
|---|---|---|
| age | 1.0162 | 0.9804 |
| amount | 1.0170 | 0.9946 |
| credit_history | 1.0306 | 0.9994 |
| duration | 1.0505 | 1.0380 |
| employment_duration | 1.0060 | 0.9962 |
| foreign_worker | 1.0004 | 0.9819 |
| housing | 1.0014 | 0.9838 |
| installment_rate | 1.0082 | 0.9807 |
| job | 0.9972 | 0.9607 |
| number_credits | 0.9964 | 0.9680 |
| other_debtors | 1.0033 | 0.9883 |
| other_installment_plans | 1.0117 | 0.9838 |
| people_liable | 1.0013 | 0.9525 |
| personal_status_sex | 0.9987 | 0.9834 |
| present_residence | 1.0033 | 0.9969 |
| property | 0.9968 | 0.9850 |
| purpose | 1.0064 | 0.9769 |
| savings | 1.0225 | 0.9894 |
| status | 1.1889 | 1.0908 |
| telephone | 1.0052 | 0.9696 |
library(ggplot2)
scores_rel |>
data.table::melt(id.vars = "feature", value.name = "score", variable.name = "method") |>
ggplot(aes(x = score, y = feature, color = method, fill = method)) +
geom_col(position = "dodge", alpha = .5) +
scale_color_brewer(palette = "Dark2", aesthetics = c("color", "fill")) +
labs(
title = "Feature Importance Scores",
subtitle = glue::glue("For task {task$id} and measure {measure$id}, using relativ scores"),
x = "Score", y = "Feature", color = "Method", fill = "Method",
caption = glue::glue("Using {resampling$iters}-fold {resampling$id}")
) +
theme(
legend.position = "bottom",
plot.title.position = "plot"
)