The goal of xplainfi is to collect common feature importance methods under a unified and extensible interface.
It is built around mlr3 as available abstractions for learners, tasks, measures, etc. greatly simplify the implementation of importance measures.
Installation
You can install the development version of xplainfi like so:
# install.packages(pak)
pak::pak("jemus42/xplainfi")Example: PFI
Here is a basic example on how to calculate PFI for a given learner and task, using repeated cross-validation as resampling strategy and computing PFI within each resampling 5 times on the friedman1 task (see ?mlbench::mlbench.friedman1).
The friedman1 task has the following structure:
\[y = 10 \sin(\pi x_1 x_2) + 20(x_3 - 0.5)^2 + 10x_4 + 5x_5 + \varepsilon\]
Where \(x_{1,2,3,4,5}\) are named important1 through important5 in the Task, with additional numbered unimportant features without effect on \(y\).
library(xplainfi)
library(mlr3learners)
#> Loading required package: mlr3
task = tgen("friedman1")$generate(1000)
learner = lrn("regr.ranger", num.trees = 100)
measure = msr("regr.mse")
pfi = PFI$new(
task = task,
learner = learner,
measure = measure,
resampling = rsmp("cv", folds = 3),
iters_perm = 5
)Compute and print PFI scores:
pfi$compute()
pfi$importance()
#> Key: <feature>
#> feature importance
#> <char> <num>
#> 1: important1 7.9320281224
#> 2: important2 8.1368297554
#> 3: important3 1.9003588453
#> 4: important4 13.5083721272
#> 5: important5 2.2748507393
#> 6: unimportant1 -0.0004293556
#> 7: unimportant2 0.0219242406
#> 8: unimportant3 0.0314298729
#> 9: unimportant4 0.0091510237
#> 10: unimportant5 0.0108304225If it aides interpretation, importances can also be calculates as the ratio rather then the difference between the baseline and post-permutation losses:
pfi$importance(relation = "ratio")
#> Key: <feature>
#> feature importance
#> <char> <num>
#> 1: important1 2.6410386
#> 2: important2 2.6853106
#> 3: important3 1.3968261
#> 4: important4 3.8012909
#> 5: important5 1.4697651
#> 6: unimportant1 0.9997936
#> 7: unimportant2 1.0044383
#> 8: unimportant3 1.0068725
#> 9: unimportant4 1.0015174
#> 10: unimportant5 1.0017192When PFI is computed based on resampling with multiple iterations, and / or multiple permutation iterations, the individual scores can be retrieved as a data.table:
str(pfi$scores())
#> Classes 'data.table' and 'data.frame': 150 obs. of 6 variables:
#> $ feature : chr "important1" "important1" "important1" "important1" ...
#> $ iter_rsmp : int 1 1 1 1 1 1 1 1 1 1 ...
#> $ iter_perm : int 1 2 3 4 5 1 2 3 4 5 ...
#> $ regr.mse_baseline : num 5.3 5.3 5.3 5.3 5.3 ...
#> $ regr.mse_perturbed: num 13.9 14.1 12.9 12.5 12.8 ...
#> $ importance : num 8.65 8.84 7.55 7.21 7.46 ...
#> - attr(*, ".internal.selfref")=<externalptr>Where iter_rsmp corresponds to the resampling iteration, i.e., 3 for 3-fold cross-validation, and iter_perm corresponds to the permutation iteration within each resampling iteration, 5 in this case. While pfi$importance() contains the means across all iterations, pfi$scores() allows you to manually visualize or aggregate them in any way you see fit.
For example:
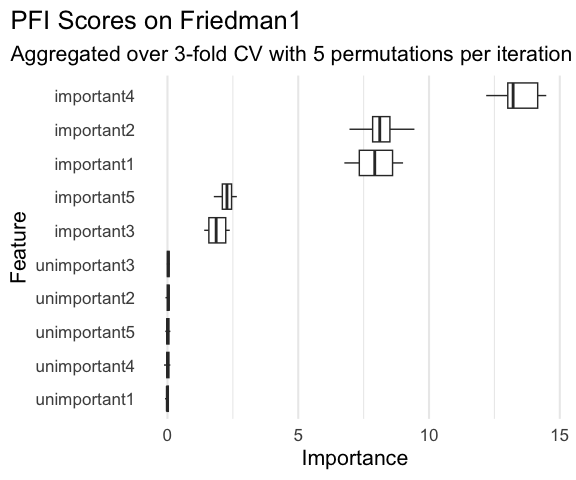
library(ggplot2)
ggplot(
pfi$scores(),
aes(x = importance, y = reorder(feature, importance))
) +
geom_boxplot(color = "#f44560", fill = alpha("#f44560", 0.4)) +
labs(
title = "Permutation Feature Importance on Friedman1",
subtitle = "Computed over 3-fold CV with 5 permutations per iteration using Random Forest",
x = "Importance",
y = "Feature"
) +
theme_minimal(base_size = 16) +
theme(
plot.title.position = "plot",
panel.grid.major.y = element_blank()
)
If the measure in question needs to be maximized rather than minimized (like \(R^2\)), the internal importance calculation takes that into account via the $minimize property of the measure and calculates importances such that the intuition “performance improvement” -> “higher importance score” still holds:
pfi = PFI$new(
task = task,
learner = learner,
measure = msr("regr.rsq")
)
#> ℹ No <Resampling> provided
#> Using `resampling = rsmp("holdout")` with default `ratio = 0.67`.
pfi$compute()
pfi$importance()
#> Key: <feature>
#> feature importance
#> <char> <num>
#> 1: important1 0.2461477003
#> 2: important2 0.3354065147
#> 3: important3 0.0534960678
#> 4: important4 0.5744520955
#> 5: important5 0.1116336289
#> 6: unimportant1 -0.0016660726
#> 7: unimportant2 -0.0031085541
#> 8: unimportant3 -0.0002086101
#> 9: unimportant4 0.0037567083
#> 10: unimportant5 -0.0022176601