Shapley Additive Global Importance (SAGE)
Source:vignettes/articles/sage-methods.Rmd
sage-methods.RmdIntroduction
Shapley Additive Global Importance (SAGE) is a feature importance method based on cooperative game theory that uses Shapley values to fairly distribute the total prediction performance among all features. Unlike permutation-based methods that measure the drop in performance when features are perturbed, SAGE measures how much each feature contributes to the model’s overall performance by marginalizing (removing) features.
The key insight of SAGE is that it provides a complete decomposition of the model’s performance: the sum of all SAGE values equals the difference between the model’s performance and the performance when all features are marginalized.
xplainfi provides two implementations of SAGE:
- MarginalSAGE: Marginalizes features independently (standard SAGE)
- ConditionalSAGE: Marginalizes features conditionally using ARF sampling
Demonstration with Correlated Features
To showcase the difference between Marginal and Conditional SAGE,
we’ll use the sim_dgp_correlated() function which creates
highly correlated features. This is similar to how PFI and CFI behave
differently with correlated features.
Model: \[(X_1, X_2)^T \sim \text{MVN}(0, \Sigma)\]
where \(\Sigma\) is a 2×2 covariance matrix with 1 on the diagonal and correlation \(r\) (default 0.9) on the off-diagonal.
\[X_3 \sim N(0,1), \quad X_4 \sim N(0,1)\] \[Y = 2 \cdot X_1 + X_3 + \varepsilon\]
where \(\varepsilon \sim N(0, 0.2^2)\).
Key properties:
-
x1has a direct causal effect on y (β=2.0) -
x2is correlated with x1 (r = 0.9 from MVN) but has no causal effect on y -
x3is independent with a causal effect (β=1.0) -
x4is independent noise (β=0)
set.seed(123)
task = sim_dgp_correlated(n = 1000)
# Check the correlation structure
task_data = task$data()
correlation_matrix = cor(task_data[, c("x1", "x2", "x3", "x4")])
round(correlation_matrix, 3)
#> x1 x2 x3 x4
#> x1 1.000 0.886 -0.021 -0.057
#> x2 0.886 1.000 -0.041 -0.059
#> x3 -0.021 -0.041 1.000 0.051
#> x4 -0.057 -0.059 0.051 1.000Expected behavior:
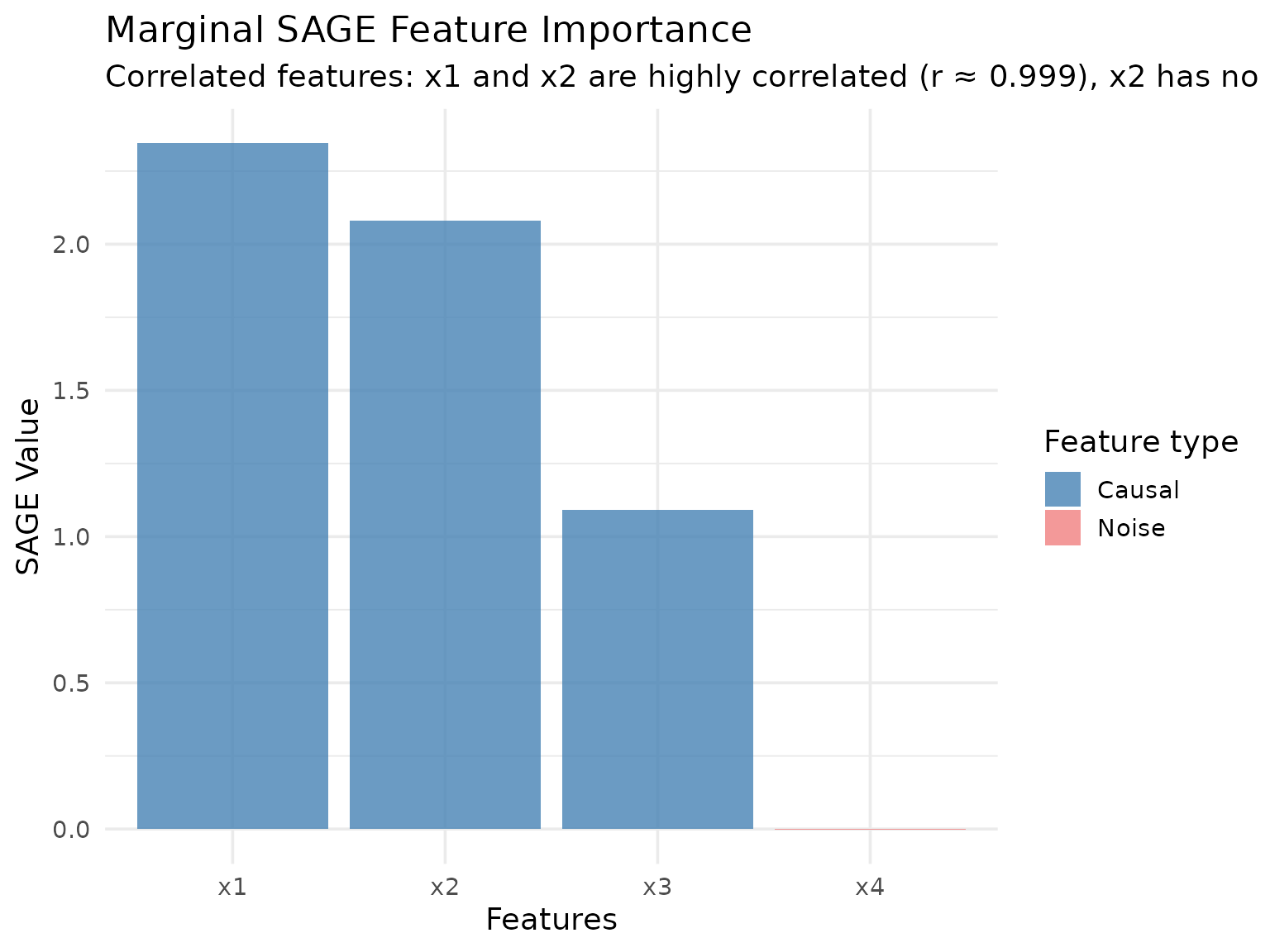
- Marginal SAGE: Should show high importance for both x1 and x2 due to their correlation, even though x2 has no causal effect
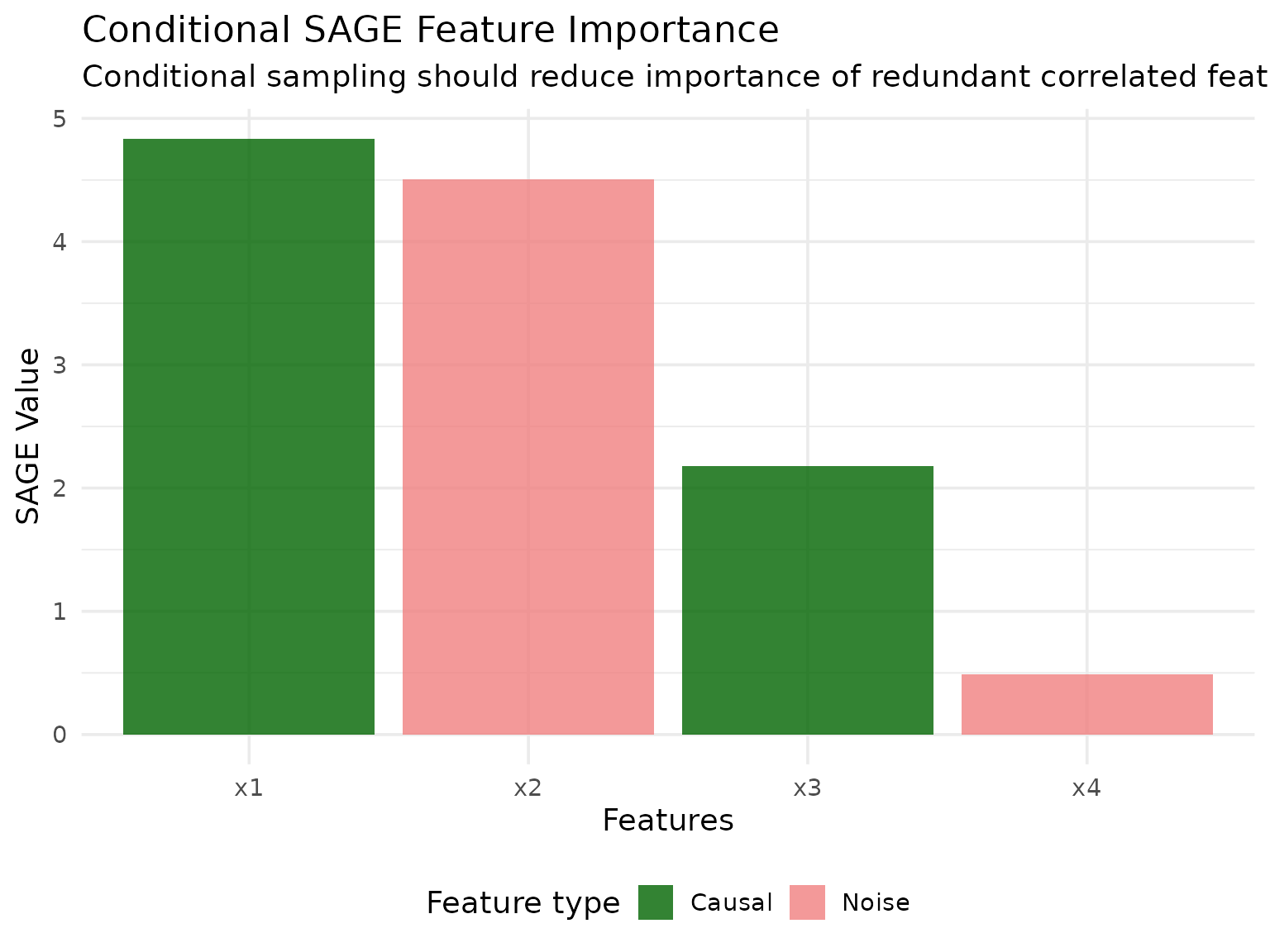
- Conditional SAGE: Should show high importance for x1 but near-zero importance for x2 (correctly identifying the spurious predictor)
Let’s set up our learner and measure. We’ll use a random forest and instantiate a resampling to ensure both methods see the same data:
Marginal SAGE
Marginal SAGE marginalizes features independently by averaging predictions over a reference dataset. This is the standard SAGE implementation described in the original paper.
# Create Marginal SAGE instance
marginal_sage = MarginalSAGE$new(
task = task,
learner = learner,
measure = measure,
resampling = resampling,
n_permutations = 30L, # More permutations for stable results
max_reference_size = 100L,
batch_size = 5000L
)
# Compute SAGE values
marginal_sage$compute()Let’s visualize the results:
We can also keep track of the SAGE value approximation across permutations:
marginal_sage$plot_convergence()
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
#> ℹ Please use `linewidth` instead.
#> ℹ The deprecated feature was likely used in the xplainfi package.
#> Please report the issue at <https://github.com/jemus42/xplainfi/issues>.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
#> generated.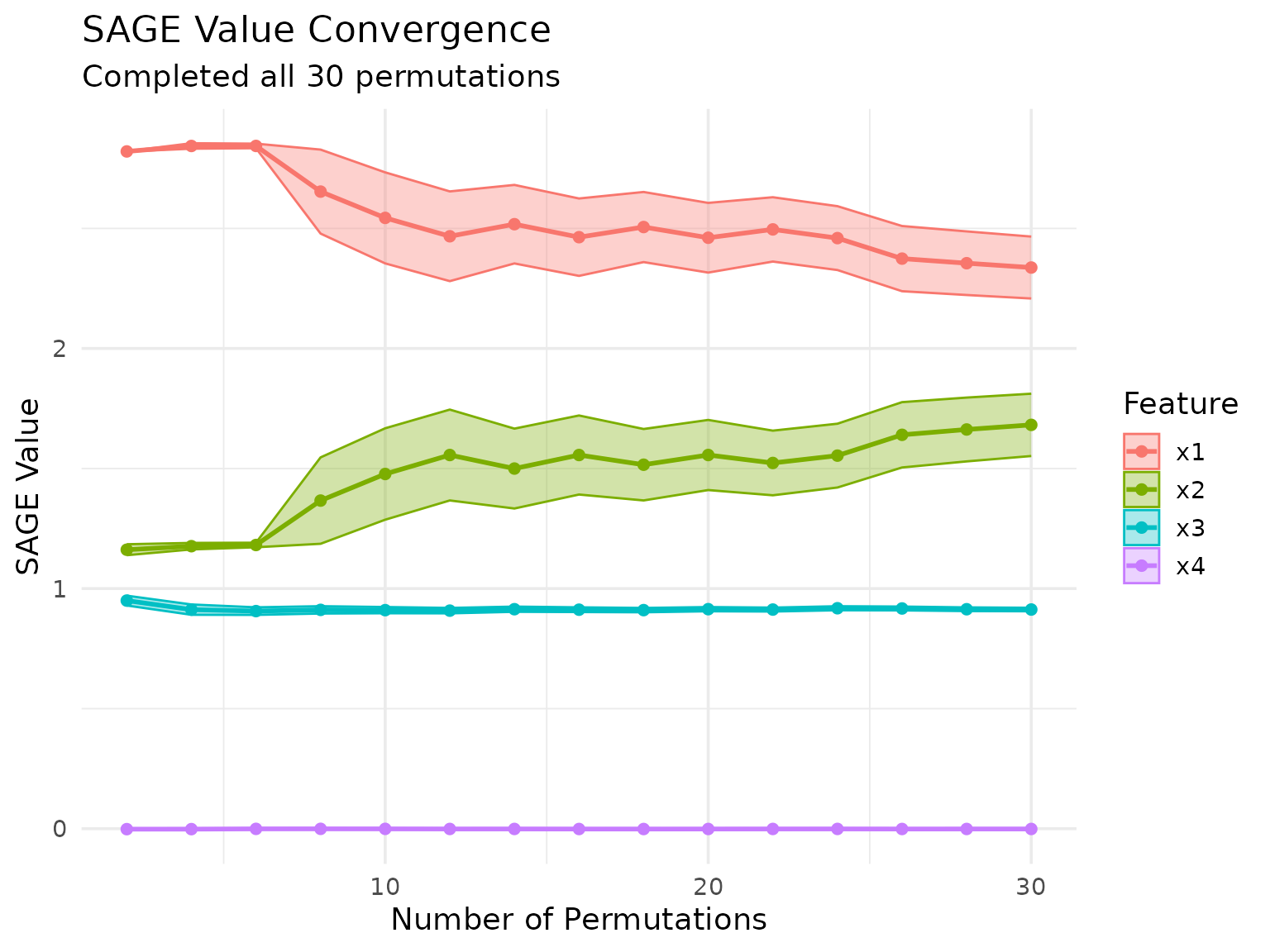
Conditional SAGE
Conditional SAGE uses conditional sampling (via ARF by default) to marginalize features while preserving dependencies between the remaining features. This can provide different insights, especially when features are correlated.
# Create Conditional SAGE instance
conditional_sage = ConditionalSAGE$new(
task = task,
learner = learner,
measure = measure,
resampling = resampling,
n_permutations = 30L,
max_reference_size = 100L
)
#> ℹ No <ConditionalSampler> provided, using <ARFSampler> with default settings.
# Compute SAGE values
conditional_sage$compute(batch_size = 5000L)Let’s visualize the conditional SAGE results:
conditional_sage$plot_convergence()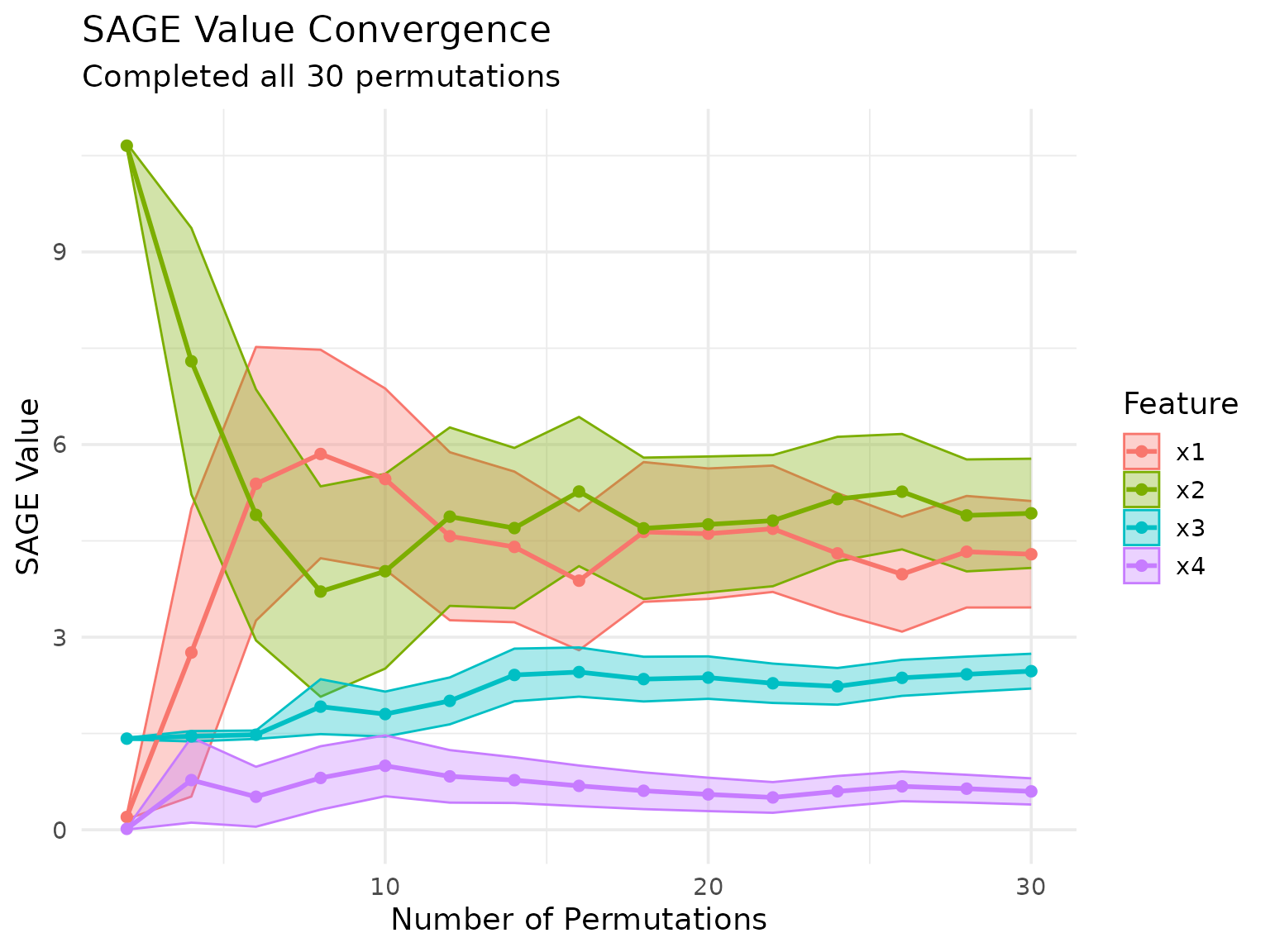
Comparison of Methods
Let’s compare the two SAGE methods side by side:
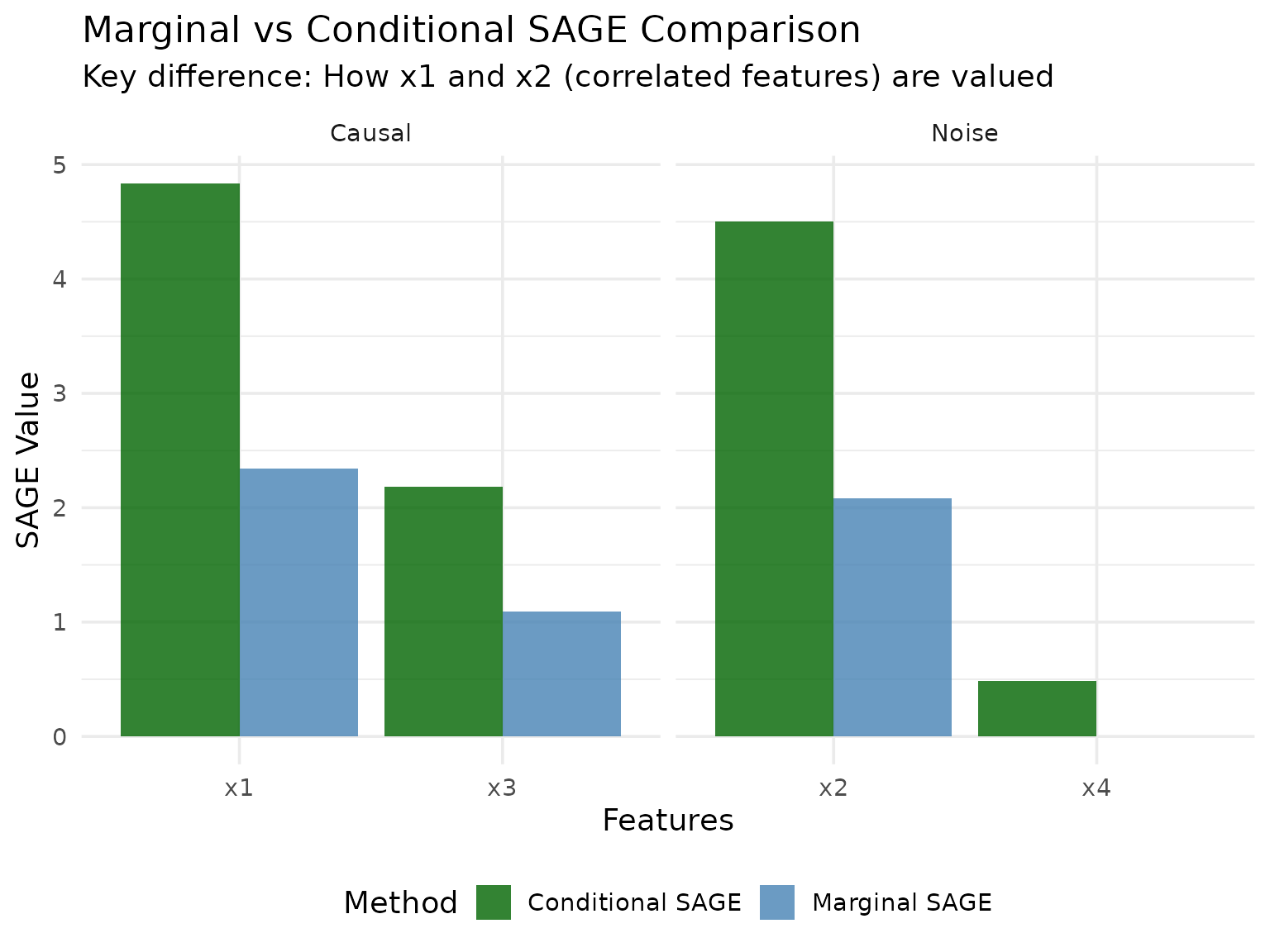
Let’s also create a correlation plot to see how similar the rankings are:
#> `geom_smooth()` using formula = 'y ~ x'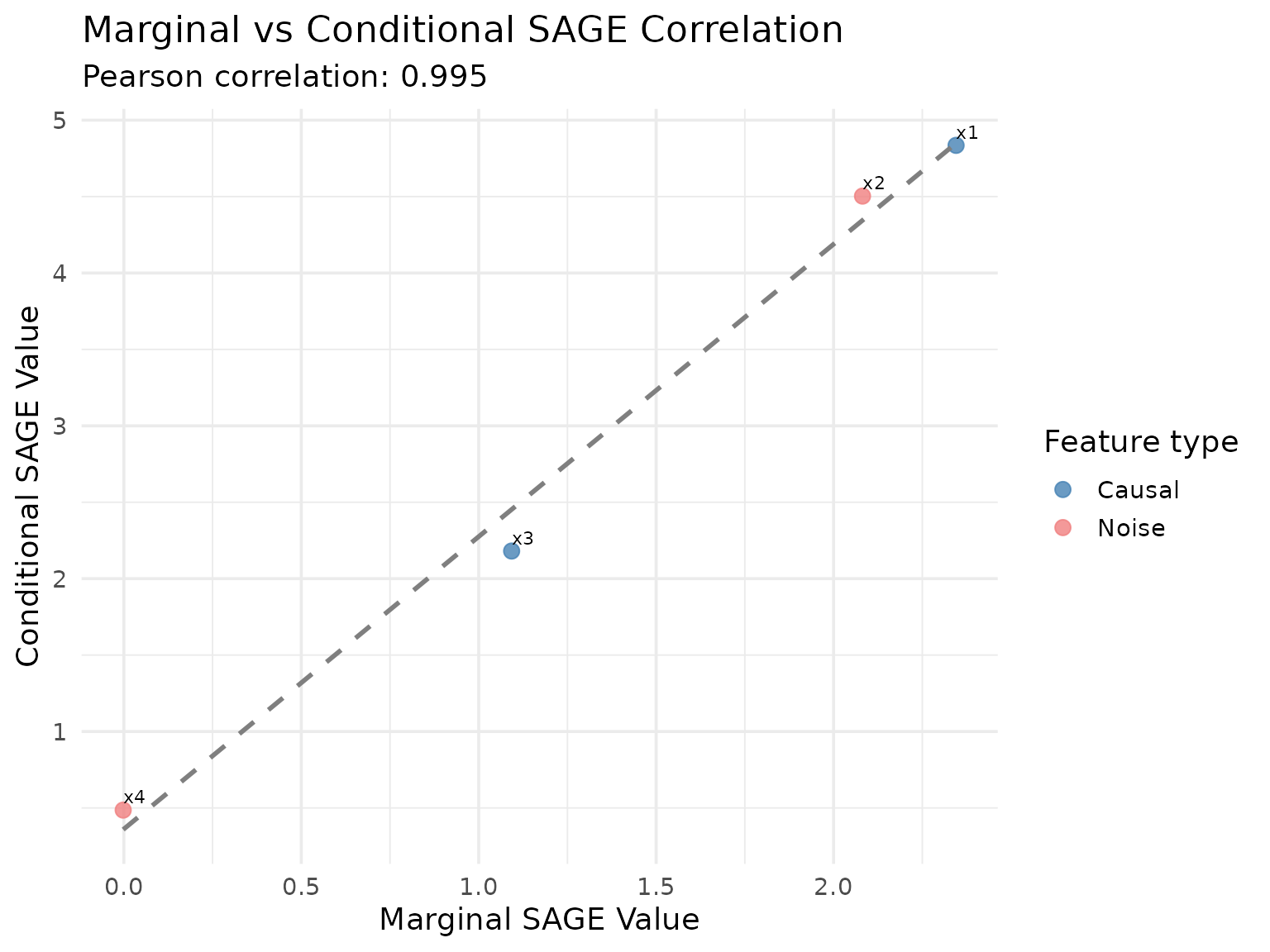
Interpretation
The results demonstrate the key difference between marginal and conditional SAGE:
Marginal SAGE treats each feature independently, so highly correlated features x1 and x2 both receive substantial importance scores reflecting their individual marginal contributions.
Conditional SAGE accounts for feature dependencies through conditional sampling. When marginalizing x1, it properly conditions on x2 (and vice versa), leading to lower importance scores for the correlated features since they provide redundant information.
Independent feature x3 shows similar importance in both methods since it doesn’t depend on other features.
Noise feature x4 correctly receives near-zero importance in both methods.
This pattern mirrors the difference between PFI and CFI: marginal methods show inflated importance for correlated features, while conditional methods provide a more accurate assessment of each feature’s unique contribution.
Comparison with PFI and CFI
For reference, let’s compare SAGE methods with the analogous PFI and CFI methods on the same data:
# Quick PFI and CFI comparison for context
pfi = PFI$new(task, learner, measure)
#> ℹ No <Resampling> provided
#> Using `resampling = rsmp("holdout")` with default `ratio = 0.67`.
cfi = CFI$new(task, learner, measure)
#> ℹ No <ConditionalSampler> provided, using <ARFSampler> with default settings.
#> ℹ No <Resampling> provided
#> Using `resampling = rsmp("holdout")` with default `ratio = 0.67`.
pfi$compute()
cfi$compute()
pfi_results = pfi$importance()
cfi_results = cfi$importance()
# Create comparison data frame
method_comparison = data.frame(
feature = rep(c("x1", "x2", "x3", "x4"), 4),
importance = c(
pfi_results$importance,
cfi_results$importance,
marginal_results$importance,
conditional_results$importance
),
method = rep(c("PFI", "CFI", "Marginal SAGE", "Conditional SAGE"), each = 4),
approach = rep(c("Marginal", "Conditional", "Marginal", "Conditional"), each = 4)
)
# Create comparison plot
ggplot(method_comparison, aes(x = feature, y = importance, fill = method)) +
geom_col(position = "dodge", alpha = 0.8) +
scale_fill_manual(
values = c(
"PFI" = "lightblue",
"CFI" = "blue",
"Marginal SAGE" = "lightcoral",
"Conditional SAGE" = "darkred"
)
) +
labs(
title = "Comparison: PFI/CFI vs Marginal/Conditional SAGE",
subtitle = "Both pairs show similar patterns: marginal methods inflate correlated feature importance",
x = "Features",
y = "Importance Value",
fill = "Method"
) +
theme_minimal(base_size = 14) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))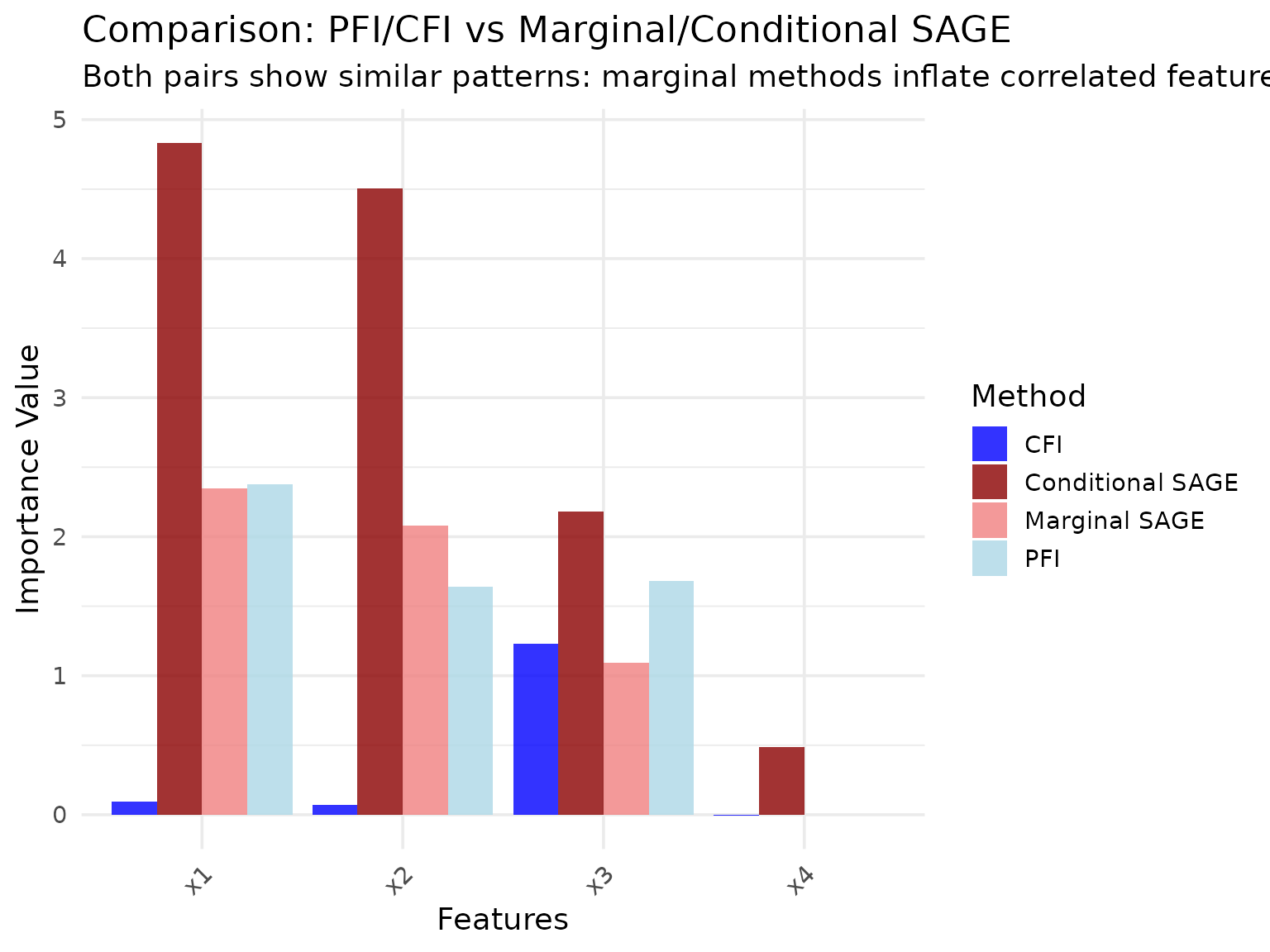
Key Observations:
- Marginal methods (PFI, Marginal SAGE) both assign high importance to correlated features x1 and x2
- Conditional methods (CFI, Conditional SAGE) both reduce importance for correlated features, accounting for redundancy
- Independent feature x3 receives consistent importance across all methods
- Noise feature x4 is correctly identified as unimportant by all methods
This demonstrates that the marginal vs conditional distinction is a fundamental concept that applies across different importance method families.