Kapitel 4 Anwendung
Als Beispiel verwenden wir hier rwm1984, ein Subset des Datensatz rwm5yr (vgl. Abschnitt 1.1, ?COUNT::rwm1984), der Angaben zur Anzahl der Arztbesuche pro Person mit zusätzlichen demographischen Merkmalen enthält. Für unser Beispielmodell verwenden wir folgende Variablen:
docvis: Abhängige Variable, Anzahl der Arztbesuche im Jahr (0-121)outwork: Arbeitslos (1), arbeitend (0)age: Alter (25 - 64)
# Daten
data(rwm1984, package = "COUNT")
# Model fit
mod_rwm <- glm(docvis ~ outwork + age, family = poisson(), data = rwm1984)
# Summary display
pander(summary(mod_rwm))| Estimate | Std. Error | z value | Pr(>|z|) | |
|---|---|---|---|---|
| (Intercept) | -0.03352 | 0.03918 | -0.8554 | 0.3923 |
| outwork | 0.4079 | 0.01884 | 21.65 | 6.481e-104 |
| age | 0.02208 | 0.0008377 | 26.36 | 3.73e-153 |
(Dispersion parameter for poisson family taken to be 1 )
| Null deviance: | 25791 on 3873 degrees of freedom |
| Residual deviance: | 24190 on 3871 degrees of freedom |
Das erste was wir zur Evaluation unseres Modells tun können, ohne direkt andere Modelle zum vergleich heranzuziehen, ist die beobachteten Counts und die auf Basis des Modells erwarteten Counts zu vergleichen, um ein grobes Gefühl für die Situation zu erhalten (Code frei adaptiert nach Hilbe (2014), p. 88f):
# Beobachtete und erwartete counts
observed_v_expected <- rwm1984 %>%
count(docvis, name = "observed") %>%
mutate(
expected = purrr::map_dbl(docvis, ~{
dpois(.x, fitted(mod_rwm)) %>%
sum() %>%
round(2)
}),
difference = observed - expected
)
observed_v_expected %>%
head(5) %>%
pander(caption = "Observed and expected counts")| docvis | observed | expected | difference |
|---|---|---|---|
| 0 | 1611 | 264.8 | 1346 |
| 1 | 448 | 627.1 | -179.1 |
| 2 | 440 | 796 | -356 |
| 3 | 353 | 731.6 | -378.6 |
| 4 | 213 | 554.6 | -341.6 |
# Mittelwert und Varianz der jeweiligen counts
# (für "expected" gilt Varianz := Mittelwert)
tribble(
~Counts, ~Mean, ~Variance,
"observed", mean(rwm1984$docvis), var(rwm1984$docvis),
"expected", mean(fitted(mod)), mean(fitted(mod))
) %>%
pander(caption = "Mean & variance of observed and expected counts")| Counts | Mean | Variance |
|---|---|---|
| observed | 3.163 | 39.39 |
| expected | 5.401 | 5.401 |
# Plot: observed vs. expected counts
observed_v_expected %>%
filter(docvis <= 12) %>%
gather(type, count, observed, expected) %>%
ggplot(aes(x = docvis, y = count, fill = type, color = type)) +
geom_point(shape = 21, color = "black", stroke = .5, size = 2) +
geom_path(linetype = "dotted", size = .25) +
scale_x_continuous(breaks = seq(0, 12, 2)) +
scale_fill_brewer(palette = "Set1", aesthetics = c("color", "fill"), name = "") +
labs(
title = "rwm1984: Poisson Modell",
subtitle = "Observed und expected counts bei overdispersion",
caption = "Output begrenzt auf docvs <= 12",
x = "Anzahl der Arztbesuche (docvis)", y = "Count"
) +
theme(legend.position = "top")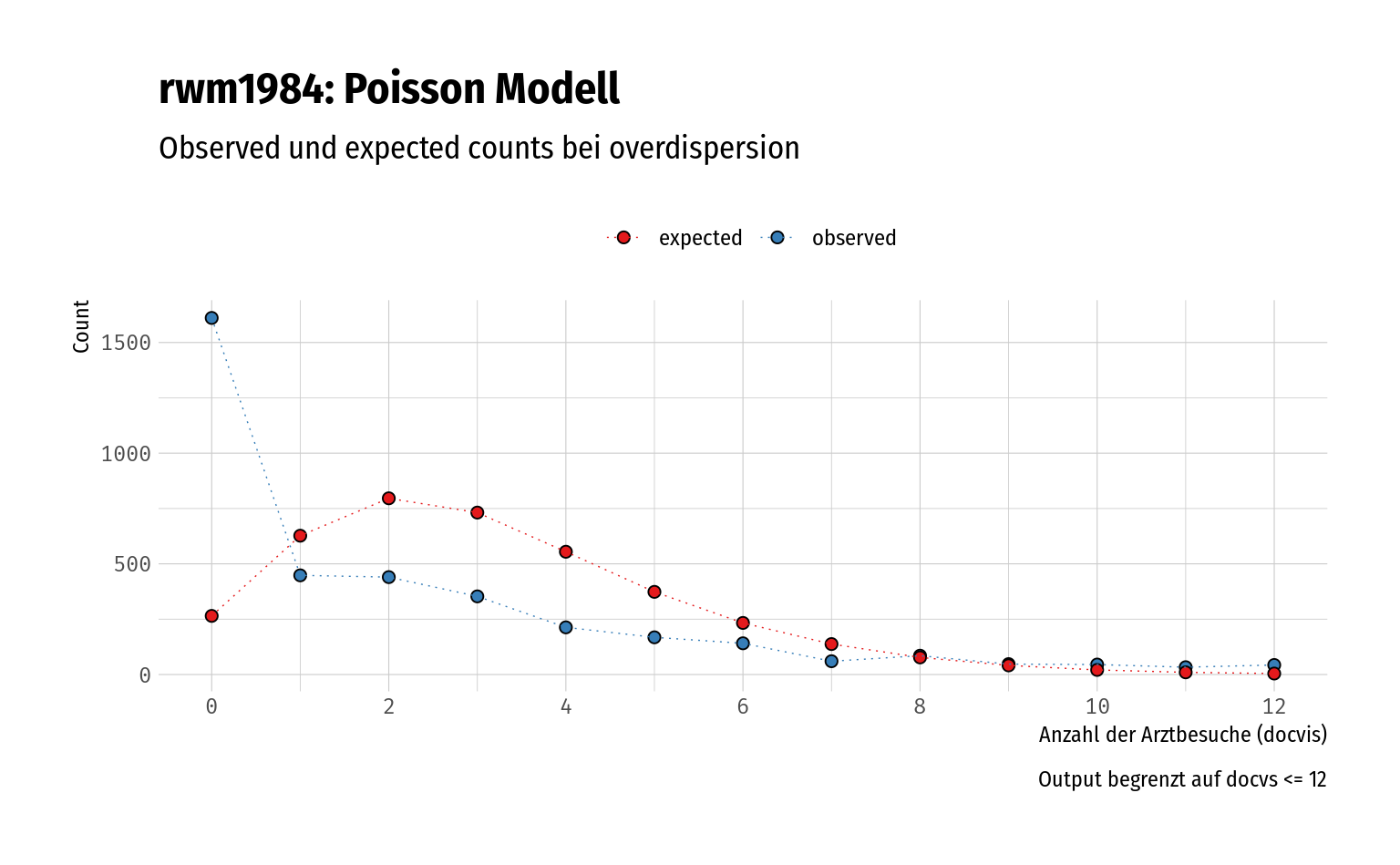
Anhand der ersten Tabelle können wir recht schnell erkennen, dass wir hier deutlich mehr Nullen beobachten als das Modell vorhersagt – mehr dazu in Abschnitt 4.2.
Der Plot veranschaulicht den eher suboptimalen model fit unter diesen Umständen (overdispersion und (bzw. bedingt durch) zero-inflation).
Literatur
Hilbe, Joseph M. 2014. Modeling Count Data. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9781139236065.